





































训练的新瓶颈不是 GPU,而是数据供应
在 AI 模型规模急速膨胀的当下,企业往往将焦点锁定在 GPU 的运算能力,随着 GPU 运算能力不断地向上提升,全新的挑战也开始一一浮现。一旦数据无法实时送达,储存系统无法实时「喂饱」GPU,昂贵的 GPU 算力资源便只能闲置空转。根据研究显示,在大型 AI 训练中,I/O 等待时间可能就占据了 30% 以上的总训练时间,直接拖慢模型收敛速度不说,更成为降低投资报酬率的隐形杀手。
然而,传统的储存效能验证多半着重于 IOPS、吞吐量等单点指标,难以反映真实 AI 训练的数据行为。企业往往在部署后才猛然发现效能瓶颈,进而引发项目延误、架构重工,甚至影响产品上市时程等连锁反应。当储存系统无法跟上数据需求时,纵使GPU 再强大,却也只能被迫闲置,造成训练时间拉长、成本上升、效能不稳定等诸多风险。
MLPerf Storage:AI储存效能测试新标竿
百佳泰结合 Golden Methodology,协助企业在不同AI训练场景下进行效能评估
为了有效克服这个难题,由 MLCommons 所制定的国际标准测试「MLPerf Storage」便应运而生,专门评估 AI 训练过程中的储存系统效能,企业方可透过统一规范进行不同储存方案的效能比较,确保硬件投资得以发挥最大效益。
百佳泰解决方案
为协助企业客户以更快、更有效率的方式进行效能评估,百佳泰除了建置完整的 MLPerf Storage 检测环境,更结合自有的Golden Methodology,提供客户MLPerf Storage验证及评估服务,包括:
- AI 效能验证:针对各类 Storage 设备进行效能检测与验证
- 效能比较分析:横跨不同 Storage 设备进行 AI 效能优劣比较,提供决策依据
为何您需要 MLPerf Storage
MLCommons 是全球领先的 AI 基准组织,目前已超过 125 家科技公司、学术单位与MLCommons研究机构进行合作。其基准检验涵盖 AI 效能、数据集、风险与可靠性评估,并在近年来成为业界公认的新标准。

MLPerf Storage 与 MLPerf Training、MLPerf Inference 同属于 MLCommons 基准检验家族,MLPerf Storage 专注于仿真真实 AI 训练的数据存取模式,而非单纯的 IOPS 或吞吐量检测。并采用虚拟加速器(Virtual Accelerators)来仿真 GPU 的数据请求模式,取代实体 GPU,藉此将评估焦点锁定在储存系统本身的效能表现,以避免受到 GPU 计算能力差异的干扰,精确揭示 I/O 与数据传输环节的潜在瓶颈。
主要工作负载
测试指标
- Training Throughput (samples/sec):每秒可处理的训练样本数,直接影响模型收敛速度。
- Training I/O Throughput (MB/sec):数据传输速率,反映储存系统能否「喂饱」GPU。
- Accelerator Utilization (AU%):GPU 忙碌比例,越高代表投资效益越佳。
百佳泰实测案例:SSD产品在不同AI训练场景下的效能差异分析
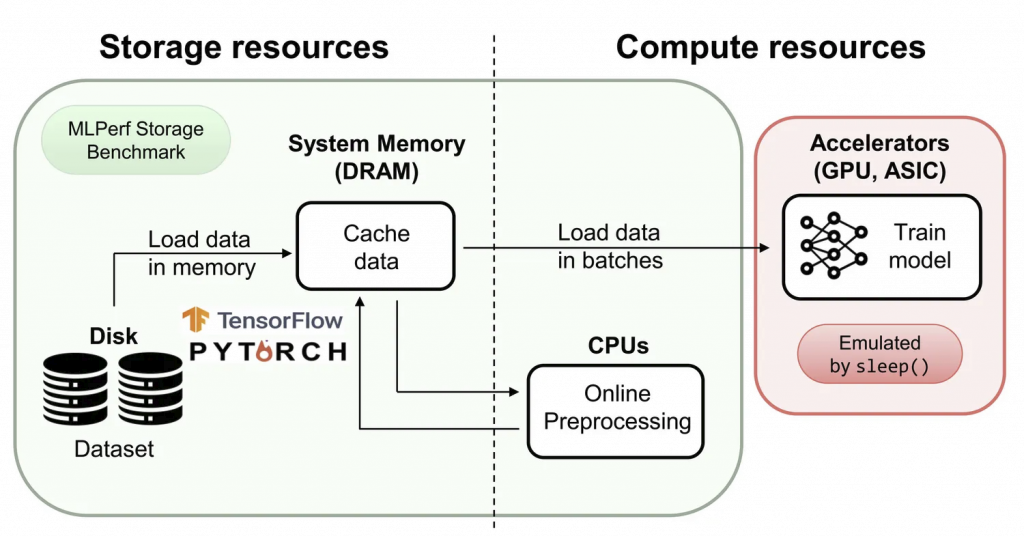
在百佳泰提供的 MLPerf Storage 验证环境中,我们针对企业级 SSD 进行了多项工作负载评估,并涵盖 ResNet50、3D U-Net与 CosmoFlow 等AI 训练场景,藉此真实反映不同数据型态(小图像、中型科学数据、大型医学影像)对储存系统的需求。本次实测主要透过模拟 NVIDIA A100 / H100 GPU 的数据存取行为,因此不需要实际 GPU,即可重现真实 AI 训练的 I/O 模式。
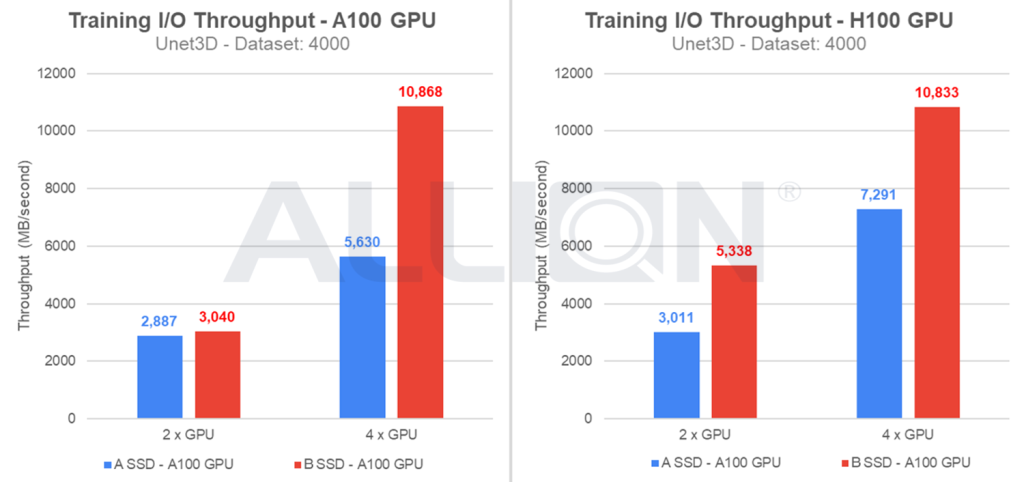
下图是使用 U-Net3D 这个模型,运行4,000个 Dataset sample 下的 Storage Training I/O Throughput (MB/sec) 比较结果。从图中我们可以看到,B 型号 SSD 的 I/O Throughput 表现明显优于 A 型号,不仅能更快速地供应训练数据,进而缩短整体训练时间。足于证明了储存效能对 AI 训练效率的直接影响。
Faster, Easier, Better!百佳泰MLPerf Storage验证评估服务
百佳泰引入 MLCommons 制定的 MLPerf Storage 国际标准,透过虚拟加速器(Virtual Accelerators)精准仿真 GPU 的数据请求模式,完整重现 AI 训练过程中的 I/O 行为。让企业在产品开发初期即可掌握储存系统在真实训练负载下的表现,而非依赖传统检测的理想化数据。
百佳泰不仅打造MLPerf Storage标准化检测环境,更结合深厚的丰富经验及项目实绩,从「产品开发除错」到「市场竞争分析」,我们以更快速、更便捷,同时更加完善的方式,提供客户专业到位的一站式顾问咨询服务。
Faster:加速产品上市,缩短模型训练周期
精准定位瓶颈,加速开发验证
百佳泰采用虚拟加速器(Virtual Accelerators)技术取代实体 GPU,进而排除运算力差异的干扰,精确揭示储存系统在 I/O 与数据传输环节的潜在瓶颈。协助开发团队能更快速地针对储存控制器或固件进行优化,大幅缩短产品除错与调校周期。
实证效能提升,展现速度优势
百佳泰的实测数据证明,优化后的 SSD 在 U-Net3D(医学影像分割)模型下,I/O Throughput 表现显著优于竞品,更能快速供应训练数据。透过我们的验证,客户产品将可进一步缩短 AI 训练时间,加速完成模型收敛。
Easier:一站式顾问服务,模拟真实场景零门坎
覆盖多元 AI 工作负载,使用情境真实模拟
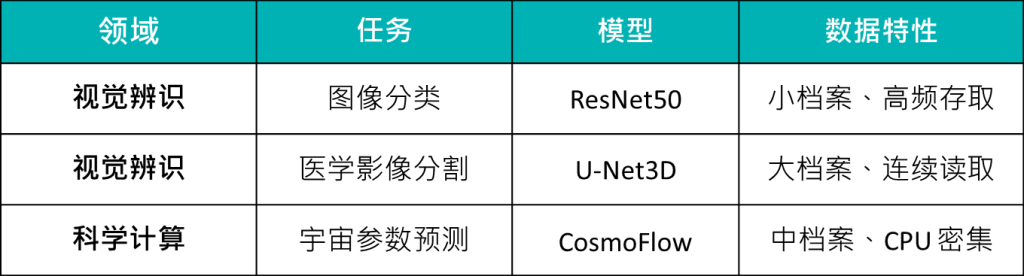
百佳泰的检测环境涵盖三大关键领域,真实反映不同数据型态的需求。客户无需自行建置昂贵的 AI 训练丛集或撰写复杂脚本,即可获取贴近真实应用场景的效能数据。
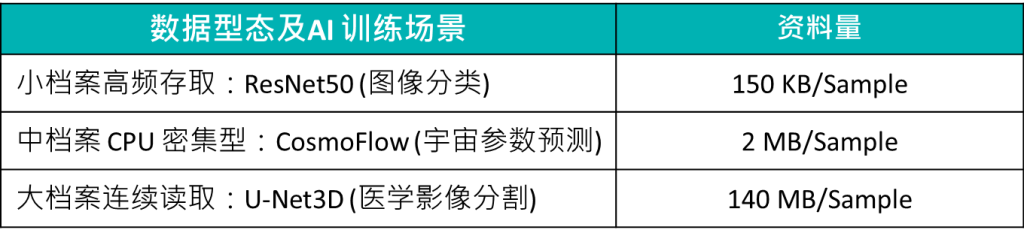
- 图像分类 (ResNet50):针对小档案、高频随机存取效能。
- 医学影像 (U-Net3D):针对大档案、连续读取吞吐量。
- 科学计算 (CosmoFlow):针对中型档案、CPU 密集型运算。
Better:客观决策依据,投资效益极大化
跨设备效能比较,提供采购决策支持
若企业客户需要在多种储存方案中进行采购决策,我们可提供您跨厂牌、跨型号的效能比较分析服务。百佳泰依据 Training Throughput (samples/sec) 与 Accelerator Utilization (AU%) 等关键指标,协助客户客观评估硬件性价比,确保每一分一毫的硬件投资都能发挥理想效益。
专业技术团队,潜在风险深入剖析
不仅止于跑分,百佳泰顾问团队更可根据实测结果进行深度分析。一旦发现产品存在潜在风险(如在高负载下的掉速或延迟),我们将协助客户厘清问题根源,并提供客制化的修正建议与解决方案,确保产品在 AI 时代具备显著质量竞争力。
若您对于MLPerf Storage有任何问题或进一步需求,欢迎透过在线窗口与我们联系,百佳泰服务团队将诚挚为您服务!
有烦恼,就来问!百佳泰专家帮你解答
不论产品、产业、生态圈,填表就能问专家!
更多成功案例






